Grundlagen der Automatischen Spracherkennung
1. Vorlesung
Link zu den Folien der ersten Vorlesung.
Organisation
Webseite: http://isl.ira.uka.de
Videos von WS17/18 auf DIVA: DIVA Videos
WS 2013/2014 auf Youtube: Playlist
Mündliche Klausur: Anmeldung über das Sekretariat (per E-Mail).
Literatur
- Xuedong Huang, Alex Acero, Hsiao-Wuen Hon: Spoken Language Processing sehr umfangreich. Mehr drin als in der Vorlesung. Schön.
- A. Waibel, K. F. Lee: Readings in Speech Recognition älter, aber zwei gute Paper.
- F. Jelinek: Statistical Methods of Speech Recognition klein, oberflächig, gutes Material zu Sprachmodellierung
- Schukat-Talamazzini: Automatische Spracherkennung PDF verfügbar
- Ivica Rogina: Sprachliche Mensch-Maschine-Kommunikation unvollständig. Download Ilias
Eindrücklicher Hinweis darauf, dass die Literatur zu lesen ist! Die Folien alleine reichen definitiv nicht aus.
“Unterschätzen Sie das nicht!”
Definition
Automatic Speech Recognition (ASR):
Definition: Automatische Umwandlung menschlicher, gesprochener Sprache in die dazugehörige Wortsequenz in maschinenverarbeitbarer Form.
Häufig fälschlicherweise als Voice-Recognition bezeichnet.
Menschliche, gesprochene Sprache ist auf Englisch: speech
Language hingegen umfasst auch Text, Gestik, Tonhöhe…
Bei ASR geht es weder um die Tonhöhe noch ob Sprecher männlich oder weiblich etc. Auch die Semantik ist in der Definition nicht enthalten. Natural/Spoken Language Understanding versucht Semantik zu erfassen.
Frage: Wie kann man Wörter korrekt niederschreiben ohne den Sinn zu kennen?
Antwort: Das geht nicht wirklich. Die immer gleichen Fehler passieren.
Lücke: Es gibt eine Lücke zwischen gesprochener Sprache und der Veschriftung. Zum Beispiel Satzzeichen. Diese sind nicht im “Signal” enthalten, der Mensch imaginiert sie sich hinzu. Sowetwas braucht die Maschine quasi auch.
Anmerkung zu den Satzzeichen: Pausen markieren nicht pauschal Satzgrenzen. Es gibt sogar Studien, die zeigen, dass mehr als die Hälfte von Pause innerhalb von Sätzen gemacht werden. (Das berühmte “Äääh” von Boris Becker.)
Anwendungsgebiete
- Diktat (überall wo man nicht schnell genug tippen kann, Hände beschäftigt)
- Untertitel für Filme (-> Durchsuchbarkeit von Videos)
- Sprachsuche, Spionage, Überwachung
- Assistenzsysteme (Blinde, Taube, körperlich Eingeschränkte)
- Pick-To-Voice-Systeme: Amazonlogistiker im Lager geben und Empfangen Befehle per Headset beim Packen von Paketen
Anmerkung: Gesprochene Sprache ist zeitlinear -> die wenigsten Menschen können diktieren.
Was sind gute Anwendungsgebiete:
- Geschwindigkeit von Eingabe erhöhen (Sprache > Stenographie > Tippen)
- Bei Verhinderung der Hände etc.
- Schon gelerntes Werkzeug - “natürliche Art der Eingabe” (vgl. Programmieren eines alten Videorecorders)
- Mikrofone sind billig, leicht und klein
- Zusätzlicher Kanal (Sprache und Knöpfe, Ausfallsicherheit)
2. Vorlesung
Nachteile der Spracherkennung:
- Umgebungen, in denen nicht gesprochen werden kann (Theater, laute Umgebung): Es gibt auch lautlose Spracherkennung: Ultraschalle am Kinn, Muskel EEG, Hirnströmungen
- Entferntes Mikrofon: Ergebnis sind dann sehr schlecht und sie werden mehr als linear schlechter mit der Distanz
Beispiel zur Distanz: Google Homepod. Veröffentlichung von Google: Eigene Mitarbeiter produzieren eine höhere Wortfehlerrate als normale Nutzer, weil sie kompliziertere Befehle ausführen wollen (20% vs 8%). Das liegt daran, dass einfachere Aufgaben “Wie wird das Wetter?” leichter zu verstehen sind und nicht alle Nuancen des Satzes benötigen im Gegensatz zu “Bestelle mir das rote Pucky-Fahrrad von Amazon für meine Tochter”.
In einem realen Projekt muss immer die erste Frage sein: “Wo kann ich das Mikrofon anbringen?” Wenn die Antwort nicht nah genug am Mund ist, dann ist es schon ein schlechtes Zeichen. Beispiel im Auto: 30 cm in der Deckenverkleidung ist schon problematisch. Beim Live-Transkribieren im europäischen Parlament (wo der Dozent wohl schon einmal mit dem Lötkolben die Mikrofonkabel angezapft hat), war es wichtig, keine Hintergrundgeräusche im Audiosignal dazugemischt zu bekommen.
Das Audiosignal von alten Kampfjets kam über den Kehlkopf früher, weil es einfach zu laut war. Heute hat man die Mikrofone vorne in der Maske.
Die Hintergrundgeräusche sind dabei immer ein Problem. Bei Autos hat man das so gelöst, dass man einen neuen Datensatz von Stimmaufnahmen mit Autogeräuschen im Hintergrund erstellt hat.
Taxonomie Sprache
Hier geht es um language.
Künstliche Sprache, zum Beispiel eine kontextfreie Grammatik mit festem Vokabular. Der Nutzer muss geschult werden. Das kann man nur mit Arbeitnehmern machen.
Normalen Anwendern kann man keine Schulung zumuten, das heißt, man möchte Spracherkennung natürlicher Sprache.
Man unterscheidet bei natürlicher Sprache drei Schwierigkeitsstufen:
- Gelesene Sprache (Vorlesen eines bereits existierenden Textes, um System zu testen)
- Geplante Sprache (Vortragen einer Rede im Bundestag sollte zwar geplant sein, aber frei gesprochen sein)
- Ungeplante Sprache (Konversationen. Und die werden immer schwieriger je kodifizierter die Kommunikation ist, was bei engen Beziehungen der Sprecher der Fall ist, zum Beispiel in einer Familie)
Taxonomie für Sprache und -erkennung
- Sprecherabhängig: Dialekte, Akzente werden darüber bedacht, dass das System auf einen Sprecher eintrainiert wird. Alte Diktiergeräte musste man 15-Minuten antrainieren, indem man ihnen einen bestimmten Text vorlaß. Andere Personen konnten das Gerät dann nicht benutzen. Wenn sich die Umgebung (Teppich statt Parkett) oder das Mikrofon verändert hat, dann funktionierten diese Systeme schnell nicht mehr.
- Geschlossene Sprechermenge, zum Beispiel in einem Parlament. Da hat man viele Trainingsdaten und kann sich auf jede Person einstellen.
- Sprecherunabhängig: Das gewünschte System
- Größe des Diskurs: Dialog versus Gruppengespräch -> unerwartete Wörter
- domänenlimitiert: Sehr große Domäne (Parlament)
- domänenunabhängig: Gibt es noch nicht wirklich (ist streitbar wie groß eine Domäne sein kann)
- Sprecherverhalten:
- kooperativ: Sprecher kennt das System nicht, will aber dass es funktioniert
- unkooperativ: Beispiel Telekom-Kundenhotline, man will gar nicht erkannt werden, wenn man sich beschwert
- Vertraut: Menschen adaptieren sich im gegenseitigen Gespräch (Spiegelneuronen), das gleiche Phänomen passiert auch bei Mensch und Maschine. Es werden sogar neue Wörter erfunden (Studie über das Bestellen eines Mobilfunkvertrages in fremder Sprache)
- Äußerungsart:
- Isolierte Wörter
- Phrasen
- Kontinuierliche Sprache
Frage: Wie funktioniert die Trennung von Kontinuum in isolierte Wörter?
Achtung! Der natürlichste Gedanke wäre, dass man sich einen Satz von unten nach oben (Phonem für Phonem) zusammenbaut, aber das ist genau, wie die guten Systeme nicht funktionieren.
Es wird mit dem ganzen Satz begonnen und der wird dann zerlegt. Von oben nach unten. (Monolithischer Block) Es werden quasi alle Sätze einmal probiert und für jeden Satz gibt es eine Wahrscheinlichkeit, circa: “Wie hätte dieser Satz geklungen, wenn er die vorliegende Audioaufnahme gewesen wäre.”
Dabei fallen dann wiederum quasi als Nebenprodukt Wort- und Phonemgrenzen ab.
Frage: Hat man bei Satzgrenzen wieder das gleiche Problem?
Antwort: Ja. Da kommt man etwas in tricksen mit Mathe. Ansätze basiernd auf neuronalen Netzen können das umgehen, sind aber noch nicht so gut…
Spracherkennung ist schwer, weil die menschliche Sprache sehr variant ist:
- Signalebene: Kein Mensch kann ein Wort zwei mal artikulieren und es produziert das gleiche Signal. Akustik, Umgebung, Mikrofone haben auch Einfluss auf das Signal.
- Phonetische Ebene: Kein Mensch spricht ein Phonem gleich aus. Alle Menschen haben eine unterschiedliche Sprache, Dialekte, Sprachfehler…
- Linguistische Ebene: Mensch ist sehr kreativ. Variation der Sätze ist sehr hoch. Analyse der Texte aus dem Wall Street Journal. Mit jeder Ausgabe gab es neue Wörter, das menschliche Gehirn lernt diese einfach dazu und erschließt sie sich. Der Computer ist noch nicht so adaptiv.
Frage: Ist Betonung ein Problem?
Antwort: Verlauf der Grundfrequenz ist ein besserer Ausdruck. Bei Deutsch und Englisch relativ irrelevant, wird teilweise ignoriert.
Experiment zum McGurk-Effekt: Immer gleiches Audioschnipsel wird über Video von unterschiedlichen Lippenbewegungen gelegt und die Menschen hören unterschiedliches, weil der Mensch indirekt Lippen lesen kann.
Ein Komilitone im Raum hatte den Effekt nicht. Mögliche Begründung, weil er als Kind die Fähigkeit aufgrund seiner Sehschwäche nicht aufbauen konnte.
Auf bei Japanern funktioniert das nicht. Unwahrscheinliche Erklärung ist aufgrund fehlenden Blickkontaktes. Wahrscheinlicher ist, dass die sichtbaren Feature (Lippen, Kinn, Spitze der Zunge) nicht hilfreich sind für das Japanische.
3. Vorlesung
Hörsaal Akustik -> abgerundete Kanzel (Schallreflektion zum Publikum wie in evangelischen Kirchen) Glatter Linoleumboden, glatte Tafel => reflektieren Schall -> Schall kommt dann unterschiedlich schnell beim Ohr des Hörers an und ergibt einen “Verschmierungs”-Effekt.
An den Wänden und der Decke sind Lochblenden zwischen denen sich der Schall verfangen kann. Menschen absorbieren Schall sehr gut.
An der Decke des Hörsaals, der auch für Videoaufnahmen genutzt wird, befinden sich Grenzflächenmikrofone, um Fragen des Publikums aufnehmen zu können. Es handelt sich um ein spezielles Mikrofon auf einer Plexiglasscheibe.
=> Warnung: Aufnahmetechnik ist sehr wichtig für Erfolg bei Spracherkennung
Lombard-Effekt Bei Blaupunkt wurde eine Freisprecheinrichtung für Autos entwickelt, die das Signal des Autoradios aus der Sprachaufnahme herausrechnen kann, wodurch das Radio bei Telefonaten im Auto an bleiben kann, jedoch nicht am anderen Ende der Leitung gehört wird. Es hat sich herausgestellt, dass die Tester des Systems vollkommen anders gesprochen haben als normal, weil sie sich der lauten Umgebung angepasst haben.
Homonyme: Gleichklänge von Wörtern mit unterschiedlicher Bedeutung
- Homographene: Man schreibt sie sogar gleich, z. B. Schloss, Schloss
- Homophone: Sie klingen gleich, aber sie werden unterschiedlich geschrieben, z. B. bis und Biss, Verse <-> Ferse
Mehrdeutigkeiten von Sätzen: “Time flies like an arrow” (Time flies like an arrow. Fruit flies like a banana.)
Spracherkennung ist Mustererkennung. Klasse ist der komplette Satz.
Folie 13: Datenübertragung ist bei 30.000 bps, aber durch Redundanz und unnützes Signal werden die 50.000 bps aufgefüllt.
Schichtenarchitektur aus Modell funktionieren nicht so top-down wie dargestellt, es existieren Beeinflussungen und Feedbackschleifen.
“Flugzeuge schlagen nicht mit den Flügeln und Autos haben keine Beine”
Gaumensegel macht den Nasenraum zu. Harter Gaumen und Zähne sind passive Artikulatoren. Impulse/Radstöße (aus der Vorlesung Kognitive Systeme) sind gut geeignet um Zerhackung des Luftstroms aus der Lunge durch die Stimmbänder zu modellieren. -> Impulszug wird moduliert
Bernoulli-Effekt Medium (Gas,Flüssigkeit) strömt durch begrenzten Kanal.
- Die Strömungsgeschwindigkeit eines Moleküls passt sich seiner Umgebung an -> der Rand des Kanals bewegt sich garnicht, daher ist außen die Flussgeschwindigkeit geringer
- Durch die unterschiedlichen Flussgeschwindigkeiten entsteht ein Unterdruck in der Mitte. -> Dieser Unterdruck zieht die Stimmlippen zusammen.
Das Zusammenziehen und Öffnen durch den Druck aus der Lunge wiederholt sich sehr oft pro Sekunde. Vergleichbar mit einem Luftballon, den man zum Quitschen bringt.
Pulmonische Sprache (pulmo = Lunge) macht fast alle menschlichen Sprachen aus, es gibt aber Ausnahmen (für uns verständliches Beispiel: Amis/Engländer machen Gluk-Gluk um Säufer zu imitieren mit dem Gaumen)
Die Frequez des Öffnen und Schließens der Stimmbänder ergibt die Stimmhöhe. Eine hohe Frequenz macht einen höheren Ton. (fälschlicherweise denken manche, dass es mit der Größe des Vokaltraktes zusammenhängt, dieser Zusammenhang besteht aber nur über die Größe der Stimmbänder; Mann Testosteron größere Stimmbänder -> Sichtbarkeit des Kehlkopfes -> niedrigere Frequenz Stimme)
Langoroskop (Kamera in Rachen) + Stroposkoplicht (Subsamplingder Bildrate) -> Aufnahmen von Stimmbändern
Mitlaute v.s. Selbstlaute
Vokale sind immer stimmhaft = Stimmbänder schwingen
Definition: Phon Kleinster Bestandteil der Spreche, der wahrgenommen wird. Der Mensch glaubt zumindest, dass da etwas ist, auch wenn manchmal im Signal nichts spezielles da ist (vergleiche mit Pausen)
Phonetiker und Linguisten nutzen die menschliche Wahrnehmung als Forschungsbasis
-> Optische Täuschungen zeigen, dass die Wahrnehmung getäuscht und interpretiert ist
Durch das exakte Scannen des Hirns können sog. Nuklei aufgenommen werden, die soetwas wie eine Taktrate haben. Diese Takte sind im Vielfachen (zum Beispiel Nucleus A ist doppelt so schnell wie B) miteinander getaktet -> Wiederum eingeschlossen in größere Nuklei, die mitunter einen Taktschlag pro 15-20 Millisekunden haben -> Das würde bedeuten, dass auf dieser Millisekundenebene gar nichts zuverlässig verarbeitet wird -> Theorie: Phone existieren nicht.
Lippenform: Flach oder rund Zungenspitze: Dorsum Linguae
Vokalviereck: Bestimmung eines Vokals durch Position des dorsum linguae und der Öffnung der Lippen. Zwei Buchstaben pro Position. Der rechte ist mit runden Lippen.
Diphtonge wandern durch das Viereck im Laufe der Artikulation. Monophtonge nicht. Vokale können auch nasal ausgesprochen werden: Franzosen
Einordnung der Konsonanten:
- Art der Artikulation
- Ort der Artikulation
- Stimmbändereinsatz (Hand an Stimmbänder halten um zu spüren, z. B. “b” vs “p”)
“Pf” ist zum Beispiel ein Phon. Es ist nicht “P” und “f” sondern zusammen wahrgenommen.
Mit wenigen Monaten können Kinder alles hören und über die Zeit lernt man dann, dass manches kein sinnvolles Signal ist oder nicht unterschieden werden muss, dann fängt man an, diese Unterschiede nicht mehr zu hören. Das sorgt für ein schwierigeres Erlernen von Fremdsprachen, wenn man älter ist, zum Beispiel russische Muttersprachlerin “Jochen” und “Johann” klingen, wegen des fehlenden Verständnis für ein aspiriertes “H”, gleich.
4. Vorlesung
Offene Konfiguration des Vokaltraktes: Vokal (vowel) Geschlossene: Konsonant
IPA = International Phonetic Alphabet herausgegeben von der International Phonetic Association
Alle bekannten Sprachlaute der Welt sollen durch ein eindeutiges Alphabet beschrieben werden können, damit man alle Sprachen so schreiben kann, wie sie klingen, wie Noten in der Musik.
Bei den Vokalen gibt es zwei Symbole, die stehen alleine und zwischen zwei Knoten. Die gibt es nur gerundet. Die grauen können theoretisch artikuliert werden, existieren aber in keiner Sprache.
Aus dem Audiosignal kann man offensichtlich nicht die Konfiguration des Vokal- traktes oder ähnliches ableiten. Daher misst man mit Metallplättchen im Mund, die man elektromagnetisch prüfen kann. Es gibt auch noch den Laryngograph (electroglottograph), dieser misst von außen am Kehlkopf. Man kann auch den Luftdruck in und außerhalb des Mundes messen, um Unterschiede bei plosiven o. Ä. zu quantifizieren.
Die gepulsten Luftströme der pulmonischen Sprache werden dann durch die Formung des Mundes moduliert. Die unterschiedlich großen Räume durch die der Schall hindurch muss, können als Helmholtz-Resonator modelliert werden. Der Helmholtz-Resonator ist eine Röhre, in der sich Wellen ausbreiten.
IPA Konsonanten: links stehen jeweils die stimmlosen und rechts die stimmhaften Konsonanten. Zum Beispiel p, b. Die lila hinterlegten Zellen sind unmöglich zu artikulieren. Leere, weiße Zellen wären möglich, aber sind noch nicht in menschlicher Sprache gefunden worden. Der Großteil der gesprochenen Sprachen ist jedoch nicht durch Linguisten oder Phonetiker erforscht worden. (Es gibt sehr viele kleine Sprachen)
Diakritika: Kleine Zeichen zur Modifikation des IPA, zum Beispiel Hochkomma für Aspiration oder Doppelpunkt nach Vokal für Streckung (Wek, weg) [vɛːɕ], [vɛk]
Die ersten paar Kapitel des IPA Handbuchs führen nochmal besser in dieses Thema ein.
Phoneme
Ein Phonem ist die kleinste bedeutungsunterscheidende Einheit einer menschlichen Sprache.
Das Phon ist unabhängig von einer spezielle Sprache; ein Phonem hingegen nicht.
Wie findet man Phoneme? Für Laien: Unterscheidung zweier Wörter durch Tausch eines Phons, zum Beispiel “Haus” und “Maus”.
Austauschbare Laute, die die Bedeutung erhalten, heißen Allophone. Beispiel: “Chemie”, “Schemie”. Das schließt aber nicht auf alle Phone, zum Beispiel gibt es trotzdem Unterscheidungen, wie “Rauch”, “Rausch”. Weiteres Beispiel ist das gerollte und ungerollte “R” im Deutschen.
Jedes Phon ist entweder Phonem oder Allophone und letzere können auch wieder zu Phonemen zusammengesetzt werden. “Monophon” <-> Allophon
Weiteres Beispiel: Im Japanischen klingen “R” und “L” gleich, daher wissen Japaner oft nicht, was genutzt werden soll, wenn sie eine Sprache sprechen in der “r” und “l” keine Allophone sind. Prinzipiell können sie aber schon “R” und “L” differenziert sprechen, es ist nur nicht nötig im Japanischen.
Die Phoneme sind nicht eindeutig definierbar. Gegenstand von Diskussionen zwischen Linguisten und Phonologen. Für Informatiker ist das nicht so wichtig. Eher die Frage, ob das Phonem geeignet ist für die Spracherkennung. Zum Beispiel: Wenn ein sehr diskutiertes Phonem (glotaler Stopp bei …) nur drei mal in 10 Stunden sprache annotiert wurde, dann ist es aus einer probabilistischen Sicht nicht so wichtig. Praktisch heißt das, dass man sie ignoriert und hofft, dass sich minimale Paare aus dem Kontext unterscheiden lassen.
Bei jeder Sprache gibt es neue Phänomene. Zum Beispiel Klicks oder nasale Vokale im Französischen. Oder tonale Sprachen.
Tonale Sprachen: Beim Englischen, wo man früher sehr viel geforscht hatte, war und ist die “Tonhöhe” (-> besser Grundfrequenz nennen) uninteressant. Im Mandarin sind sie aber bedeutungsunterscheidend. Dort gibt es fünf Töne: steigend, fallend, bergförmig, flacher Ton und unbetonter Ton. Beim Kantonesischen sind es sogar 8 Töne + der flache Ton = 9. In afrikanischen Zulu-Sprachen wird es noch mehr, denn dort ändert sich die Tonhöhe mit der Stelle des Wortes im Satz…
Physik Wellen
Schall ist eine Longitudinalwelle. Kleine Auffrischung von Schulwissen:
Ruhe Luftdruck auf NN 1013 mbar (Millibar).
Schalldruck: Wechseldruck in Pascall ($ {N \over m^2} [Pa] $), der zum Ruhedruck hinzukommt. Der leisteste hörbare Schall hat einen Schalldruck von 1e^-5 Pa. Die Schmerzgrenze für den Menschen liegt bei 63 Pa. -> 10 Milliarden mal größer als das Leiseste => großer dynamischer Umfang
Schall kann als eine Überlagerung von sinoiden Wellen modelliert werden.
T = Dauer für eine Schwingung Frequenz f = 1/T [Hz]
James Clerk Maxwell hat die Theorie aufgestellt, die elektromagnetische Wellen vorstellt. Deren Existenz wurde durch Hertz nachgewiesen (1/s ist 1 Hz):
Schall breitet sich mit begrenzter Geschwindigkeit (abhängig vom Medium) aus. Wellenlänge $ l = {c \over f} $
Dazu ein kleines Video, das den Zusammenhang zwischen elektromagnetischen Wellen und deren Frequenz illustriert:
Schalldruckpegel: $ L_{p} = 10 log_{10} ( { \tilde{p}^2 \over p_{0}^2 } ) [dB] $ oder $ L_{p} = 20 log_{10} ( { \tilde{p} \over p_0} ) [dB] $.
Wobei $\tilde{p}$ der vorzeichenbereinigte Schalldruck und $p_0$ der Referenzdruck $2 * 10^{-5} Pa$. Ursprünglich wurde letzteres für die Hörschwelle bei 1 kHz gehalten. Jetzt leicht anders, aber man passt die Referenz nicht mehr an, daher kann es zu zu negativen Werten in niedrigen Bereichen kommen, da: $log(x) < 0$ für x kleiner 1.
Die Wahl des Logarithmus spiegelt auch das menschliche Empfinden beim Schall, da er nicht linear als lauter empfunden wird.
dezi Bell gibt es auch bei Elektromagnetismus, daher nutzt man in der Akustik noch ein angehängtes “A” für “Akustisch”: dB (A)
| Referenz | Ungefährer Schalldruck [dB (A)] |
|---|---|
| $P_{}$ | 0 |
| Kühlschrank | 40 |
| Schreien | 65 |
| Konzert (ab hier beginnt das Gehör Schaden zu nehmen) | 120 |
| Gewehrschuss (ab hier beginnt Schmerzgrenze) | 140 |
| Raketenstart | 180 |
Man beachte, dass die Schmerzgrenze leider erst nach der Schadensgrenze beginnt.
Schallenergie: Zusammensetzung aus kinematischer und potentieller Energie. Modellannahme: Luftteilchen, die an fiktivem Punkt mit einer fiktiven Feder verbunden sind. “Aufziehen” und “Zurückschwingen” (siehe Erklärung zu Helmholtz Resonator)
Energie wird Schall zugewiesen. Schalldruck und Energie verhalten sich unterschiedlich bezüglich der Distanz.
- $E ~ { 1 \over r^2 }$: die Energie verhält sich umgekehrt, quadratisch proportional zum Radius
- $P ~ { 1 /over r}$: der Druck hingegen umgekehrt linear proportional
Die Schallwelle breitet sich als Kugel aus -> Oberfläche der Kugel -> quadratische Abnahme der Energie ???
Das Ohr
Ohrmuschel dient als Empfänger.
Druck auf Trommelfell von außen unterschiedlich. Die Longitudinalwelle wird am Trommelfell in eine mechanische Bewegung übertragen. Über Steigbügel, Hammes und Amboss findet dann eine Verstärkung des Signals auf eine kleinere Fläche statt. Ovales Fenster Dieses Ovale Fenster überträgt die mechanische Bewegung in eine Wanderwelle auf die Flüssigkeit innerhalb der geschlossenen Schnecke (latein Cochlea). Es handelt sich um eine stehende Welle.
Die Schnecke wird nach hinten immer schmaler. Dadurch findet sich zu jeder Frequenz ein Abschnitt der Cochlea mit einer passenden Resonanzfrequenz. Das heißt, es gibt dort besonders starke Wechseldrucke. Salopp: “Es schwappt dort besonder viel Wasser hin und her”.
Ungefähr: Diese Resonanz wird übertragen und an der basal membran auf die Haarzellen übertragen, welche dann das Signal in elektrische Reize überführen.
Mehr Infos: https://de.wikipedia.org/wiki/H%C3%B6rschnecke
Effekte:
- Es ist nicht immer nur ein Resonanzbereich aktiv
- Schwingungen überlagern sich
=> komplexe Muster
Aktivierung eines Neurons: Es gibt ein Mindesniveau zum Aktivieren eines Neurons. Davor feuert es nicht, sondern regeneriert sich nur. Aktivierungspotential. Die notwendige Zeit zum Aktivieren eines Neurons ist länger als die Dauer, einer Schwingung eines Haars an der Cochlea. Daraus folgt, dass der Mensch Schallwellen nur beschränkt genau auflösen kann. Es gibt also Frequenzunterschiede, die kann der Mensch nicht hören. -> pychoaktive Effekte Diese “Lücke” wird zum Beispiel bei der Codierung von MP3 verwendet, um die Datenrate reduzieren zu können.
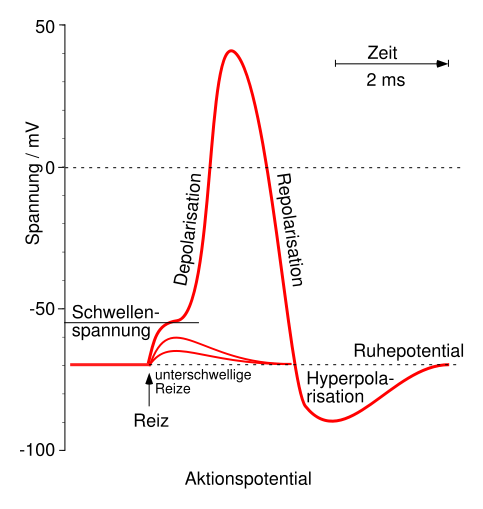
https://de.wikipedia.org/wiki/Aktionspotential
5. Vorlesung
Das Frequenzspektrum (oft auch nur Spektrum) eines Signals, gibt dessen Zusammensetzung aus verschiedenen Frequenzen an. Ein Frequenzband bezeichnet einen Bereich in einem Frequenzspektrum. Den Abstand zwischen der unteren und oberen Grenzfrequenz heißt Bandbreite.
Die kritische Bandbreite ist der Mindestabstand (minimale Breite), damit zwei Töne vom Menschen als unterschiedlich wahrgenommen werden können.
Dadurch kann es zu spannenden Phänomenen kommen.
Wenn man sich anschaut, was eine an das Ohr angelegte Frequenz bewirkt, dann kann man sich die Frequenzantwort der Basilarmembran anschauen. Hier entstehen Überlagerungen und Kurven:
- niedrige Töne: eher breit und näher an einer Glockenform
- hohe Töne: weniger glockenförmig, Kurve mit Plateus
Dieses Wissen kann man nutzen, um Kompressoren zu designen.
Menschl. Empfinden
Menschen haben ein subjektives Lautstärkeempfinden, das nicht direkt mit Schalldruck und -energie zusammenhängt.
Um zu messen, wie laut ein Mensch was empfindet, gibt es die Einheit Phon:
Der Wert in Phon gibt an, welchen Schalldruckpegel (dB) ein Sinuston mit einer Frequenz von 1000 Hz besitzt, der gleich laut empfunden wird, wie das eigentliche Schallereignis, das eine eigene Frequenz besitzt. Daduch ist es möglich, Hörempfinden mit einem Pegelwert zu beschreiben, der unabhängig vom Spektrum des Signals ist.
“Ein Lautstärkeunterschied von etwa 1 phon liegt als Unterschiedsschwelle gerade so an der Grenze der Erkennbarkeit. Deshalb ist es weder nötig noch sinnvoll, Bruchteile eines Phon anzugeben.” Null Phon ist die Hörschwelle.
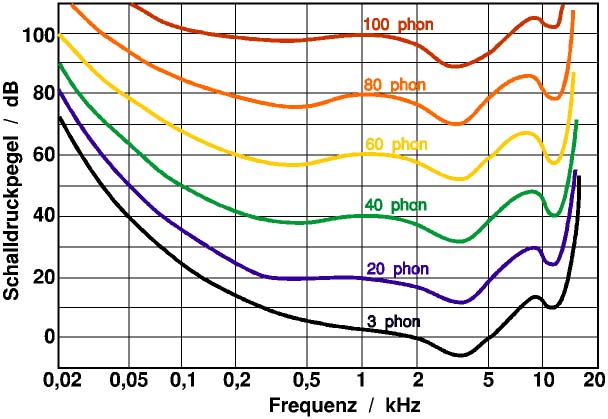
Die Linien bedeuten, dass der Sinuston den gleichen Schalldruckpegel hatte. Man spricht von der Phon-Skala.
Absolutes Gehör: Die Frequenz eines Tones kann unabhängig von der Lautstärke erkannt werden. Stüker meint, dass es sich um eine genetische Disposition handelt in Verbindung mit Training. Normale Gehöre lassen sich durch Lautstärke täuschen, wodurch zum Beispiel ein Ton mit geringerem Schalldruck für tiefer gehalten werden kann.
Rauschen: Es handeld sich um ein Schallsignal, das aus vielen unterschiedlichen Frequenzen und Energieanteilen zusammengesetzt ist.
Wenn man Menschen einem Rauschen aussetzt, dabei aber ein gewisses Frequenzband auslässt, dann sind die Neuronen an der Basilarmembran für “leergepumpt” bis auf die, die das Frequenzband ablesen können. Dadurch entsteht nach Abschalten des Rauschens ein Effekt, dass die Probanden überempfindlich in diesem Frequenzband sind.
Weiteres Experiment: Wenn man zwei nah beeinander liegende Frequenzen (Abstand zum Beispiel 2 Hz) in ein Signal mischt und es Menschen vorspielt, dann werden sie nicht als zwei Töne wahrgenommen, sondern ein hin und her schwingen. Das nennt man auch Schwebung.
Wenn der Frequenzunterschied etwas größer ist, dann wird das Signal als “rauer Ton” wahrgenommen (40 Hz Unterschied). Und wenn sie dann ausreichend weit entfernt sind, dann kann der Mensch sie als zwei Frequenzen wahrnehmen.
Schriften
Um nun Niederschreiben zu können, was in einem Signal erkannt wurde, benötigt man Schriften. Zu Beginn der automatischen Spracherkennung hat man nur im Englischen gearbeitet und daher war das lateinische Alphabet ausreichend.
Für ASR ist ein “Aussprachewörterbuch” sehr wichtig: Wie klingt ein Wort, wenn es aus diesen Phonemen zusammengesetzt ist.
Es gibt auf der Welt einige Schriftsysteme. Prof. Stüker findet, dass David Christobal eher ein “McDonalds-Linguist” ist, das heißt, es wird von vielen Nicht-Linguisten gelesen und es ist streitbar, was er schreibt.
Einteilung der Schriftsysteme in sechs Klassen:
-
Logosyllabisch: Ein Zeichen entspricht einem Wort oder einer Silbe. Zum Beispiel die chinesische Schrift. Laut Wikipedia: “Die chinesische Schrift (chinesisch 中文字, Pinyin zhōngwénzì, Zhuyin ㄓㄨㄥ ㄨㄣˊ ㄗˋ) oder Han-Schrift (漢字 / 汉字, hànzì, Zhuyin ㄏㄢˋ ㄗˋ) fixiert die chinesischen Sprachen, vor allem das Hochchinesische, mit chinesischen Schriftzeichen. Sie ist damit ein zentraler Träger der chinesischen Kultur und diente auch als Grundlage der japanischen Schriften (Kanji, Hiragana, Katakana), einer vietnamesischen Schrift (Chữ nôm) und einer der koreanischen Schriften (Hanja). Insgesamt gibt es über 100.000 Schriftzeichen[1], von denen der überwiegende Teil jedoch heute nur selten verwendet wird bzw. ungebräuchlich ist, in der Vergangenheit nur zeitweilig verwendet wurde oder Varianten darstellt. Für den alltäglichen Bedarf ist die Kenntnis von 3.000 bis 5.000 Zeichen ausreichend. “
Auch die Hyroglyphen sind ein Schriftsystem, da sie auch Zusammensetzungen können. Es handelt sich nicht nur um Bilder. Argumentation nach Daniel (Linguist): Es handelt sich nur um eine Schrift, wenn abstrakte Ideen dargestellt werden können. Das ist bei Piktogrammen nicht der Fall. Man benötigt ein Konzept von Silben oder Buchstaben.
- Syllabisch: Zeichen entsprechen einer Silbe. Zum Beispiel Cherokee.
- Abjad: Zeichen enstprechen Konsonatent. Abjad heißt ABC auf Arabisch, Namen der ersten drei Zeichen. Arabisch und Hebräisch. Problem: Gleiche Schriftliche Darstellung eines Signals, aber unterschiedliche Aussprache, weil Vokale nicht enthalten.
- Alphabet: Zeichen entsprechen Vokalen und Konsonanten. Alph, bet sind die ersten beiden Buchtaben des Herbäischen. Interessant also, dass Alphabet nach einem Abjad benannt ist und nicht Griechisch. Hier gibt es auch mehrere Laute für Buchstaben in gewissen Kombinationenn, zum Beispiel Diphtonge oder |sch|. Das Phonem wird nicht so ausgesprochen, wie seine Einzelteile. -> Das kommt daher, dass sich die Sprache entwickelt hat, aber die Schrift nicht angepasst wurde. Witz von Alex Waibel: Ein Deutscher, ein Franzose und ein Engländer gehen in eine Bar. Alle nennen den Namen ihres Hundes und sagen, das schreibt man wie man es spricht. Beim Engländer ist es aber überhaupt nicht klar. Generell englische Städtenamen, kann man ihre Aussprache nicht gut von der Schrift ableiten. Beim Englischen ist der Unterschied groß, weil die Schrift sehr alt und wenig verändert wurde.
- Abugida: Jedes Zeichen steht für einen Konsonanten und einen ihn beigleitenden Vokal. Das Zeichen kann durch Diakritika modifiziert werden, um andere Vokale darzustellen. Abugida leitet sich aus den ersten vier Konsontanten+Vokalen des Äthiopischen ab.
- Featural: “Die Form der Zeichen steht in Beziehung zu Merkmalen des Sprachsegments, für das sie stehen.” Also alles andere. Problem: Verschriftlichung des Signals klappt nicht gut.
Die wenigsten Sprachen sind geschrieben. An vielen Orten dieser Welt gibt es gesprochene Sprachen, aber die Schrift kam bei vielen erst im Nachhinein. Junge Sprachen bekommen oft ein Alphabet. Kolonien haben es oft aufgedrückt bekommen, zum Beispiel Vietnam.
Vietnam hatte auch Hanse, dann kamen Missionare und haben dem Vietnamesischen eine Alphabetschrift mit Diakritika aufgezogen.
In den Phillipinen: Tagallok hat erst sehr spät überhaupt eine Schrift bekommen.
Mikrofone
Alle Mikrofone haben eine Membran. Sie unterscheiden sich in Bauform und Wandlerprinzip. Beim Wandlerprinzip ist zu beachten, ob man Schallenergie oder Schalldruck messen möchte. Ersteres ist empfindlicher gegenüber Distanz.
- Dynamisches Mikrofon: An die Membran ist ein Magnet befestigt, der sich bei Schwingung durch eine Spule bewegt. Dadurch wird abhängig von Stärke des Magnet und Fläche des durchdringenden Feldes elektrischer Strom induziert. Die Geschwindigkeit der Membranschwingung kontrolliert die Stromstärke in der Spule. Das Signal ist proportional zur Membrangeschwindigkeit. Alle dynamischen Mikrofone sind Geschwindigkeitsempfänger.
- Kondensatormikrofon: Eine starre und eine bewegliche Kondensatorplatte. Die bewegliche ist mit der Membran verbunden, wodurch sich bei Annäherung der beweglichen Platte die angelegte Spannung erhöht. Die absolute Auslenkung ist abhängig vom Druck. Es wird also der Schalldruckpegel gemessen und dieser ist nicht so empfindlich ggü. Distanz. $P ~ {1 \over r}$ Alle Kondensatormikrofone sind Elongationsempfänger (es wird also die Auslenkung der membran gemessen)
- Elektretmikrofon: Die Kondensatorplatte an der Membran ist blöd und benötigt eine Gleichspannungsquelle. Daher wird die Membran mit einer Elektretfolie überzogen, welche dauerhaft positiv geladen ist, indem ihr Elektronen entnommen wurden. ~90% aller Mikrofone heutzutage sind Elektretmikrofone, weil sie billig hergestellt werden können. Aber eigentlich wäre es wünschenswert, dass zum Beispiel beim Telefonieren keine Kondensatormikrofone verbaut wären, damit man keine Hintergrundgeräusche hört.
- Kohlemikrofon: Stromfluss durch Kohlepulver ist besser, wenn Kohle unter Druck gesetzt wird (durch Sprache). Sehr lange in Telefonhörer, deswegen musste man sie auch auf den Tisch hauen von Zeit zu Zeit, um den Kohlegries durchzuschütteln.
- Piezomikrofon: Piezo-Kristall wird durch Membran berührt und das induziert einen Stromfluss. -> Das hatte aber einen zu hohen Klirrfaktor. Anteil hochfrequenter Schwingungen. Erinnert an klirrendes Glas.
Bühnenmikrofone sind in der Regel dynamische Mikrofone, weil sie empfindlich ggü. Distanz sind. Die Membran wird mit Gitterkäfig und Schaumstoff geschützt.
Als Linearität von Mikrofonen bezeichnet man die Qualität der Übertragung des Schallsignals in ein elektrisches Signal. (1 kHz -> 1 kHz ?)
Minitiatisierungseffekte werden bei Studiomikrofone für gewöhnlich mit Größe kompensiert.
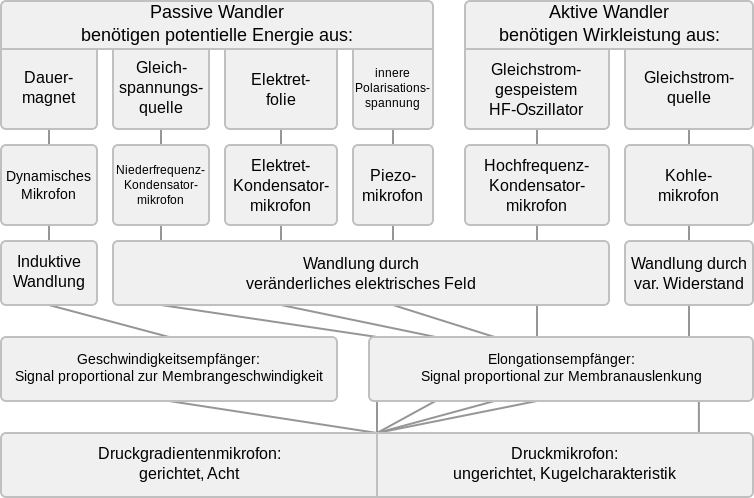
Richteigenschaft
Die zweite Eigenschaft von Mikrofonen ist die Richtcharakteristik.
- Druckgradientenmikrofon: Gerichtet, achterförmig. Von vorne oder hinten wird der Druckunterschied an der Membran gemessen. An den Seiten ist das nicht möglich.
- Druckmikrofon: Ungerichtet, kugelförmig. Eine Seite der Membran geht in eine Box, in die der Druck von außen nicht so leicht hineinkommt. Dadurch kann das Signal von allen Richtungen aus gleich stark gemessen werden. In der Box ist der Druck konstant. Es gibt nur ein kleines Loch, welches einen Druckausgleich wie beim menschlichen Ohr erlaubt.
Der Druckausgleich beim menschlichen Ohr passiert durch eine Verbindung zwischen Innenohr und Rachen.
Zusätzlich gibt es dann noch das Grenzflächenmikrofon: Man stellt es auf eine glatte Fläche, damit es den Schall von überall her einsammeln kann, der auf der glatten Fläche reflektiert.
Das Richtmikrofon (Richtrohrmikrofon) ist eine Röhre, die nur den Schall aus einer speziellen Richtung begünstigt. Es ist kein Verstärker, man kann nur das aufgenommene Signal elektrisch verstärken, da wenig Umgebungsgeräusche dabei sind.
Es gibt auch noch das Parabolmikrofon, welches wie bei einer Satelitenschüssel wirkt und tatsächlich das Signal verstärkt.
Der Pop-Schutz: Schaumstoff soll niederfrequente Anteile (Atmen, Wind) herausfiltern. Feine Pohren filtern. Das große Mikrofon, das an der Nordsee verwendet wird, nennen die Tontechniker “tote Katze”.
6. Vorlesung
Geschichte ASR
Wie alt ist ASR? Nach der Kenntnis von Prof. Stüker 1913 mit dem “Voice Operated Typewriter”. Funktioniert analog mit elektromagnetischen Filtern. Kurzzusammenfassung des
Artikels: “Vokale klappen, Konsonanten nicht, weil sie zu kurz sind”
Noch vor der ASR gab es Sprachsynthese.
1846: Euphonia - Sprachsynthesemaschine in England von Joseph Faber.
Konstruiert wie ein Instrument, das den Vokaltrakt und eine Lunge nachstellt (ähnlich Orgel).
Konnt sogar “flüstern” und “singen”, dass können die aktuellen Systeme
nicht so gut. Die Frau Faber hatte sogar Konzerte damit gegeben.
1922: Radio Rex - Ein Spielzeughund, der auf 500-Hz-Filterbank anspringt und dann
aus seinem Haus gefedert wird. Das liegt so beim Buchstaben “e” wodurch
der Hund scheinbar auf das Wort “Rex” herauskommt.
1939: Voice coder (Vocoder) - entwickelt von Dudley für Militär. Aufteilung
des Signals in Fenster (Abtastung), Glättung,
Übertragung (kann jetzt verschlüsselt sein) und zum Schluss wieder Synthese
Dadurch konnte man Telefonie verschlüsseln für das Kampffeld.
1946: Visible Speech von Bell. Dieser kam sowieso aus dem Bereich der
Arbeit für Hörgeschädigte.
1965: Fast Fourier Transform (FFT). Sehr wichtiger Algorithmus, weil dadurch
viele Aufgaben der Signalverarbeitung digital gelöst werden konnten.
Oft sogar in Hardware gegossen.
1968: Dynamic Time Warping für Spracherkennung von Vintsyuk. Dieser hatte es zu
diesem Jahr erfunden. Die Amis dachten bis zum Fall des Eisernen Vorhangs,
das es bei ihnen zuerst erfunden wurde.
1971: DARPA SUR Projekt (bis 1976). Zwischen 69 und 71 hat ein sehr großer
Fortschritt stattgefunden. DARPA ist aus der Mondlandung entstanden und
bekannt für viele Projekte: frühes Internet, Robotik, Autonome Autos
1975: Von Forschern aus DARPA SUR wurde HARPY gebaut. Diese nutzten
Hidden Markow Models (HMM), was bis heute immernoch der Standard ist.
Sie erzielten bereits auch schon eine gute Perplexität, was ein
Fehlermaß in Relation zu den bestehenden Auswahlmöglichkeiten ist.
1985: Kontextabhängige HMMs. Danach wurden es immer mehr Daten und mehr
Rechenleistung, die zur Verfeinerung der bestehenden Modelle genutzt wurden.
2000: Sprache-zu-Sprache (VERBMOBIL) https://www.youtube.com/watch?v=noZBab-Lmss
2006: GP-LVM und danach Emmissionswahrscheinlichkeit durch neuronale Netze ersetzen
2018: Trend geht in die Richtung, dass man HMM durch NN ersetzen will, aber
State-of-the-Art ist weiterhin HMM.
WER
Word Error Rate, Wortfehlerrate auf Deutsch. Es handelt sich um ein Gütemaß für die Funktionsfähigkeit von ASR. Dazu nimmt man eine transkripierte Audioaufnahme und vergleicht das Transkript dann mit dem Ergebnis des ASR. Dazu nutzt man die Levenshtein-Distanz, welche auch Minimale Editierdistanz (Minimum Edit Distance) genannt wird. Diese bezeichnet die minimale Anzahl an Einfügungen (INSERT), Löschungen (DELETION) und Ersetzungen (SUBSTITUTION), welche man benötigt, um von der Hyptothese (Ergebnis des ASR) zur Referenz aus dem Transkript zu kommen.
Wobei “#” für die Anzahl an Operationen und N für die Anzahl an Wörtern in der Referenz steht.
Die Wortakkuratheit ist $accuracy = 1-WER$.
Wie findet man die minimale Editierdistanz? Dazu gibt es ein Verfahren mit dynamischen Programmieren in quadratischer Zeit.
| H | A | L | L | O | ||
|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | |
| H | 1 | 0 | 1 | 2 | 3 | 4 |
| A | 2 | 1 | 0 | 1 | 2 | 3 |
| U | 3 | 2 | 1 | 1 | 2 | 3 |
| S | 4 | 3 | 2 | 2 | 2 | 3 |
Die Zeile ist die Hypthese und die Spalte die Referenz. Wir wollen Hypthese in Referenz umwandeln. Die Frage für Zelle X,Y ist quasi immer: Wie viele Operationen benötige ich, um von meinem Wort aus der ersten Zeile bis zum Buchstabe X eine Umwandlung in das Wort der ersten Spalte bis Y durchzuführen.
Man muss aber gar nicht mitdenken, wenn man die Regel kennt. Wenn die beiden Buchstaben nicht gleich sind, dann nimmt man das Minimum von (links, oben oder links-oben) und addiert eins dazu. Dadurch kann man die Tabelle stupide ausfüllen.
Der Wert der dann am Ende bei der vollen Länge in der Tabelle steht (unten rechts) ist die Anzahl der nötigen Operationen.
Bemerkungen
- Die WER kann größer sein als 100%. Zum Beispiel kann das WER einfach sehr viel mehr Wörter erkennen als im Satz enthalten sind.
- Die WER kann nicht negativ werden, da weder Nenner noch Zähler negativ werden können
- Es gibt mehrere Operationsfolgen, um die minimale Editierdistanz zu finden.
Die WER als Fehlermetrik ist ganz nett, aber hat einige Haken. Bei maschineller Übersetzung zum Beispiel gibt es mehrere valide Übersetzungen. Oder wenn eine Segmentierung in Wörter nicht so leicht ist (Chinesisch Han-Schrift). Oder wenn Fehler unterschiedlich zu bewerten sind. Zum Beispiel in einem medizinischen Spracherkennungssystem verändert das Wort “nicht” einfach alles, obwohl es nur ein Wortfehler von eins ist.
NIST Benchmark Mai 2009 von ASR Systemen (Stüker sagt, dass NIST gut messen kann. “Sie betreiben die Atomuhr und prüfen Böller.”)
Früher hatte man Sprachverstehen und Spracherkennung noch miteinander behandelt. Im Englischen: Speech Understanding and Recognition (SUR)
Am Anfang der 1990er war man dann bei einem 1000-Wort-Datensatz bereits auf menschlicher WER (2 - 4%), also hat man neue, größere, schwierigere Datensätze genutzt. Nicht nur Vorgelesenes, dann auch Meeting und freie Sprache. Je größer das Vokabular desto größer auch der Fehler.
Die Testsets wurde nach Mikrofonaufbau unterschwieden, weil es einen erheblichen Unterschied gemacht hat:
- Kreis: Nahbesprechungsmikrofon
- Viereck: Single distant microphone
- Triangle: Multiple distant microphones (komplexe Zusammenführung der Aufnahmen)
Die Distanz macht große Probleme. Dieses Thema ist dann wieder mit Alex und HomePod spannend geworden. Diese nutzen sog. Mikrofonarrays mit zum Beispiel acht Mikrofonen. Die Mikrofon-Arrays (Triangle) aus dem Benchmark hatten auf eine Distanz von circa 6-7 Metern 64 Mikrofone.
Ab 2000 hat man dann auch mal neue Sprachen hinzugefügt und hatte dann bei gleicher Wörterzahl höhere WER. Das lag daran, dass Mandarin zum Beispiel tonalisch ist und das Schriftsystem anders, wodurch erst ein paar Jahre daran gearbeitet werden musste.
WER können abhängig von der Aufgabe überall zwischen 4 - 90% sein. Marketing ist hier oft irreführend.
Signalverarbeitung
In Elektrotechnikbüchern nach “Systemtheorie” suchen, um Hintergrundwissen zu bekommen.
Kurz und knapp: Warum Signalverarbeitung in der ASR? Unwichtiges Rausschmeißen und wichtiges Hervorheben. Wenn das System nämlich mit Rauschen oder redundanten Signalen antrainiert wird, dann lernt es diese im schlimmsten Fall und hat dann weniger Parameter übrig, um andere Merkmale zu lernen.
Beispiele für zu entfernende Signale:
- Sprecheridentität
- Akustischer Raum (Hall, absolute Lautstärke)
- Mikrofon
Häufig geht das nicht. Manche Dinge bekommt man aber ganz gut raus, z. B.:
- Lautstärkeschwankung
- Bestimmte Sprecheridentitäten
Es geht jetzt in diesem Teil der Vorlesung darum, sich einen Baukasten der Signalverarbeitung zuzulegen.
System
Ein System T wandelt ein eingehendes Signal in ein anderes um. Bei uns handelt es sich um eine diskrete Folge von Werten (digital):
Einfaches Beispiel: Zeitliche Verzögerung $y[n] = x[n - n_d]$ wobei $n_d$ den Delay (Verzögerung) definiert.
Weiteres Beispiel: Moving Average
Ein lineares System kann “innen oder außen” skaliert werden:
Das waren Beispiele für lineare Systeme (LS). Wenn ein LS zeitinvariant ist, dann nennt es sich Linear Time-Invariant system. Wenn die Eingabezeit verzögert wurde, dann soll das Ergebnis der Transformation trotzdem das gleiche sein.
Ein System heißt zeitinvariant, wenn gilt: $ y_1[n] = y[n - n_d] $
Mit diesen kann sehr gut gerechnet werden.
Dirac Stoß
Es handelt sich bei der Dirac-Distribution nicht um eine Funktion, sondern eine Distribution.
d(x) ist der Diracstoß am Zeitpunkt x. Welcher bei x unendlich groß ist und sonst null. Zusätzlich gilt die Einschränkung, dass die Fläche unter d(x) 1 sein soll, was in dieser Kombination keine Funktion auf den reellen Zahlen bieten kann.
Ist eigentlich nicht integrierbar, weil d(x) nicht integrierbar. Kann aber über die Diracfolge ausgedrückt werden:
Man kann den Dirac-Stoß aber als Verteilung darstellen und zwar zum Beispiel durch eine Gaußglocke, die bekanntermaßen die Fläche 1 hat. Wenn man die Varianz nun gegen 1/unendlich gehen lässt, dann erhält man folgende Annäherung:
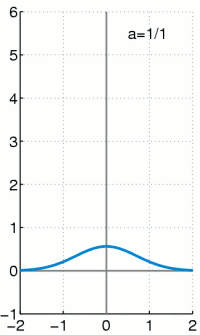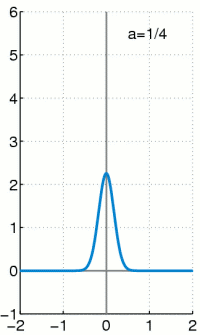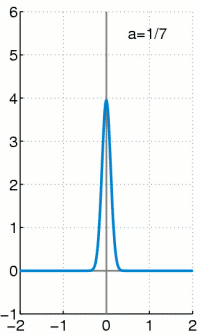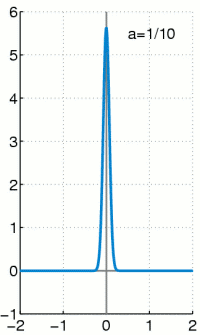
Entsprechend wird für das Rechnen angenommen:
Das Integral eines Diracstoßes multipliziert mit einer Funktion g(x) = g(0). Wenn man Zeit nun verschiebt, dann kommt man auf die Siebeigenschaft:
Im diskreten Fall schreibt man:
$\delta[n] := 1 $ wenn $n = 0$, sonst $0$
Siehe Dirac-Kamm.
Faltung
Mit der Faltung kann man die Wirkung eines Kanals auf ein Signal modellieren. Sie ist salopp gesagt die Wirkung, die ein Signal auf ein anderes hat.
Sie ist:
- Kommutativ: f * g = g * f
- Assoziativ: f * (g * h) = (f * g) * h
- Distributiv: f * (g + h) = f * g + f * h
- Assoziativ mit Skalar: a (f * g) = (a f) * g = f * (a g)
Eine Faltung entspricht einer Multiplikation im Frequenzbereich.
Impulsantwort
Die Impulsantwort, auch Gewichtsfunktion oder Stoßantwort genannt, ist das Ausgangssignal eines Systems, bei dem am Eingang ein Dirac-Impuls zugeführt wird. Definiert als:
Wenn y[n] = T {x[n]}, dann gilt durch die Siebeigenschaft:
Wenn T linear, dann:
Wenn T auch noch zeitinvariant (-> LTI):
Das heißt, dass die Ausgabe eines LTI Systems als eine Faltung des angelegten Signals mit der Impulsantwort berechnet werden kann.
Beispiel: Ein Raum mit Mikrofon sei ein LTI. Ich erzeuge eine Annäherung an den Dirac-Stoß, wie zum Beispiel ein “Chirp”, welches in einer Sekunde alle Frequenzbereiche einmal durchgeht. Beim aufgenommenen Signal tut man jetzt so, als sei das die Impulsantwort.
Quelle-Filter-Modell
Die Quelle erzeugt ein Schallsignal mit einem bestimmten Spektrum (stimmhafte Laute oder weißes Rauschen durch Atmen), das bis zur Abstrahlung an den Lippen einen Resonator (den Vokaltrakt) durchläuft, welcher das Signal mit einer bestimmten Übertragungsfunktion verformt. Da es sich auch hier um ein lineares System handelt, kann man das Spektrum des abgestrahlten Sprachsignals dadurch erhalten, daß man das Spektrum der Quelle mit der Übertragungsfunktion des Filters multipliziert. Ein anderer - aber mathematisch äquivalenter - Weg ist die Faltung des Quellesignals mit der Impulsantwort des Filters im Zeitbereich.
Dabei ist zu beachten, daß es sich bei der Quelle nicht nur um die stimmhaft angeregte Glottis handeln muß. Ebenso kann der Resonator, der Hohlraum im Vokaltrakt, je nach Lage der Quelle sehr komplexe Formen annehmen (z.B. bei Ankopplung des Nasenraums).
Also: Schallsignal $u_n$ wird erzeugt und durch Vokaltrakt v und Lippen r moduliert. Das kann man als eine Faltung des Signals sehen. Was wir dann messen am Mikrofon ist: $f_n = u_n * v_n * r_n$
Um an das Originalsignal zu kommen müsste man die Faltung invertieren, was schwer ist.
7. Vorlesung
schreiben
12.11.2018
Fourier
schreiben
DFT
schreiben
FFT
schreiben
Ein Teile-und-Hersche-Algorithmus zur Berechnung der DFT. Wird oft in Hardware gegossen.
ToDo: Wie funktioniert es?
8. Vorlesung
schreiben
14.11.2018
Aufzeichnungen fehlen mir…
9. Vorlesung
schreiben
19.11.2018
Formanten
Die Resonanzfrequenz f des Helmholtz-Resonator hängt von der Größe der Öffnung S und dem Gasvolumen V ab.
$ f = ~ sqrt{S}$ $ f = ~ { 1 \over sqrt{V} }$
Die verstärkten Resonanzfrequenzen nennt man Formanten. Sie sind als starkes Auftreten der Oberschwingung sichtbar im Spektrogramm. Sie entstehen durch eine Selbstverstärkung durch Inferenzen im Helmholtz-Resonator.
Die niedrigste Frequenz F1 nennt sich erster Formant. Trägt man F1 und F2 für die amerikanischen Vokale auf, dann bekommt man das Vokaldreieck. Es heißt so, da sich alle Vokale in einem Dreieck befinden. Das sollte man nicht verwechseln mit dem Vokalviereck. Die Bestimmung von F1 und F2 ist manuell geschehen. Die Frage war dann damals, ob man Vokale anhand F1 und F2 erkennen kann. Sie sind zwar geclustert, aber nicht 100% scharf abgetrennt und zudem ist die automatische Identifikation von F1 und F2 schwer, da man bei einer falschen F1-Erkennung einen hohen Fehler erhält.
LPC
Linear Predictive Coding also lineare Vorhersage.
Nach dem Quelle-Filter-Modell kann man Sprache als LTI sehen:
Das heißt, dass sich das zukünftige Signal als Kombination der alten Werte und einem Fehler zusammensetzt.
Die Z-Transformierte der Impulsantwort des LTI:
Es handelt sich um einen Quotienten aus Polynomen, wobei der Zähler nur eine eins ist. Deswegen gibt es keine Nullstelle. Der Nenner kann Polstellen hervorbringen. Da das Modell nur Pole und keine Nullstellen hat, nennt es sich All-Pole-Modell.
Wie findet man die $a_k$? Dafür muss man den Fehler minimieren: $e[n] = s[n] - \widetilde{s}[n]$
Wir setzen $a_o = 1$. So kann man die LPC-Koeffizienten $a_k$ finden. Diese werden gerne in der Spracherkennung als Merkmale verwendet.
Die Werte der Z-Transformierten auf dem komplexen Einheitskreis approximieren das Spektrum. Das Problem: Nasale haben Interferenzen zwischen Abstrahlern, die sich eliminieren können, dadurch entstehen sich auslöschende Schwingungen.
Das ist ungünstig, da wir im All-Pole-Modell keine Nullstellen darstellen können.
Vergleicht man die LPC-Koeffizienten mit DFT-Koeffizienten, dann sind man, dass LPC eine Glättung des Spektrums bewirkt.
Es gibt zwei Probleme damit:
- Es gibt keine Nullstelle
- Wie wählt man die Auflösung richtig (Anzahl Koeffizienten)
Cepstrum
Wortspiel mit Spektrum.
Durch die einmalige Anwendung der Fouriertransformation gelangt man in den Frequenzbereich. Durch die Anwendung der Inversen FT jedoch nicht wieder zurück in den Zeitbereich, sondern in den Cepstral-Bereich.
Durch Anwendung des Kontinuierlichen und monotonen Logarithmus wird aus der Multiplikation eine Addition.
Unter der Annahme, dass das Zeitsignal eine Faltung unterschiedlicher Signale ist, kann man das Cepstrum “entfaltend” nennen, wodurch man auf das ursprüngliche Signal kommt.
Wenn e also schätzbar, dann kann man es abziehen. Dafür muss man die Impulsantwort von e errechnen. e ist aber eher unbekannt.
Das Cepstrum ist eigentlich eine komplexe Funktion. Das darstellbare Cepstrum (“real”) kann man als FT des Leistungsspektrums sehen. Die Einheit der x-Achse nennt man Quefrenz.
Vielfaches der Grundfrequenz wiederholt sich immer wieder. Das ist sichtbar im Quefrenz-Bereich.
Wichtig: Die Signalenergie fließt nur in die Berechnung des 0-ten Koeff. ein. Daher wird er häufig durch die Signalenergie ersetzt. Das heißt, dass das Signal bis auf den 0-ten Koeff. lautstärkenagnostisch ist.
Liftering
Die unteren Koeffizienten des Cepstrums beschreiben die Makrostruktur des Signals. Die oberen die Mikrostruktur. Die oberen Koeffizienten setzt man auf Null und nennt das in Anlehnung an “filtering” liftering.
Meistens wählt man 13 Koeffizienten zur Weiterverarbeitung.
Häufiger Verarbeitungsablauf:
Mel-skalierte Cepstral-Koeffizienten:
- Signal
- -> FT
- Spektrum
- -> Spektrum-Mel-Skalierung
- Mel-Spektrum
- -> $FT^{-1} (log(\cdot))$
- Mel-Cepstrum
Man spricht auch von Mel-Frequez-Cepstrum und den Mel-Frequnz-Cepstrum Coeffients (MFCC)
DCT
In der Praxis wird statt der $FT^{-1}$ eine Diskrete Cosinus-Transformation (DCT) verwendet.
DCT-II ist definiert als:
Die Inverse der DCT-II ist die DCT-III:
Bei JPEG findet dieses Verfahren ebenfalls Anwendung. Man entfernt ebenfalls die hohen Frequenzanteile und kann dann mit einer dünnbesetzten Matrix ein Huffman-Coding.
Mel-Filterbank
Durch Anwendung einer Mel-Filterbank auf ein Spektrogramm, die die höheren Frequenzen ungenauer erfasst als die niedrigen, reduziert man die Anzahl der Koeffizienten von zum Beispiel 8000 auf 40.
Durch das Cepstrum mit Liftering entsteht eine Art Glättung im rekonstruierten Leistungsspektrum.
Typ. Vorverarbeitung
- Digitales Signal (16 kHz Abtastrate, 16 Bit Auflösung)
- Fensterung (Hamming-Fenster mit 16ms Breite, 10ms Verschiebung) -> pro Fenster (Frame) 256 Abtastwerte/Samples
- DFT: 256 komplexe Werte
- Betragsspektrum: 256 reelle, symmetrische Werte -> nur die Hälfte nötig: 128 reelle Werte
- Mel-Skalierung auf 24-40 Werte
- Logarithmus: 24 - 40 Werte
- DCT: 24-40 Werte
- Liftering: 13 Werte
Dynamische Merkmale
Spektrum und Cepstrum bilden nur statische Eigenschaften ab, aber der Verlauf der Formanten verläuft einer Dynamik. Wohin bewegt sich ein Formant?
Dafür approximiert man zum Beispiel die 1. und 2. Ableitung im Diskreten durch Differenz zu vorherigem Frame. Es werden also aus 13 Mel-Cepstral-Koeffizienten 39 Werte.
Autokorrelation
t beschreibt die Verschiebung des Signals. Mit diesem verschobenen Signal vergleicht man das Signal selbst. Bei t=0 liegt die obere Grenze, weil das Signal mit sich selbst maximal ähnlich ist. Dieser Wert ist proportional zur Leistung des Signals. Es treten Spitzen auf, wo Wiederholungen sind
Die Grundfrequenz macht sich im Signal durch Oberschwingungen mit der Frequenz bemerkbar. Die erste Spitze ist die Grundfrequenz, aber nicht so gut erkennbar. Wenn man hier bei der Entfernung einen Fehler macht, dann einen großen. Dagegen hilft Glättung, weil menschliche Stimme nicht enorm springt. Warum will man die Grundfrequenz haben? Zum Beispiel wichtig für tonale Sprachen und Prosodieanalysen.
Nulldurchgangsrate
Wie oft wechselt das Signal das Vorzeichen? Weil bei Stille eine geringere Nulldurchgangsrate als bei Sprache vorliegt, kann man so die beiden voneinander trennen.
Dim Red
Dimensionanalität reduzieren
PCA
Hauptkomponentenanalyse: Projiziere Merkmale in einen niederdimensionalen Raum und erhalte dabei so viel Varianz wie möglich. Zum Beispiel durch Berechnung der Eigenvektoren der Kovarianzmatrix. Diese Eigenvektoren nutzt man dann als neue Hauptachsen.
Die Kovarianzmatrix wird diagonalisiert bei der PCA, was den Effekt hat, dass die Merkmalsvektoren dekorreliert werden.
Ein Paradebeispiel für einen Datensatz, der durch die PCA nicht nicht besser trennbar wird, ist das Adidas-Problem.
LDA
Dieses Problem kann durch die Lineare Diskriminanz Analyse gelöst werden. Bei dieser Methode sind die Klassenzugehörigkeiten der Datenpunkte bekannt und es wird angestrebt die einzelnen Klassen maximal voneinander und in sich kompakt zu halten.
Die Klassenseparabilität einer Klasse soll maximiert werden. Danach Kullback–Leibler-Divergenz maximieren. Es handelt sich um ein Maß für die Unterschiedlichkeit zweier Wahrscheinlichkeitsverteilungen.
Wird in der Praxis verwendet.
NN
Vorverarbeitung durch Neuronale Netze. Interpretation der Ausgabe als posteriori Wahrscheinlichkeit von Phonemen, Polyphonen oder Sub-Phoneme.
Man nutzt dabei ein größeres Fenster (200-500 ms) einer herkömmlichen Vorverarbeitung, zum Beispiel Cepstrum.
Also auch wieder als eine Vorverarbeitung. Und dann wieder alle Daten zusammenführen in einem großen Vektor. Darauf kann man dann wieder LDA anwenden.
Bottleneck Features
Man kann das Neuronale Netz auch benutzen, um eine niederdimensionale Repräsentation erhalten. Dafür führt man einen Flaschenhals in die Topologie ein und trainiert weiterhin auf Klassifizierung in Phoneme etc. Dann nutzt man die Aktivierungen im Flaschenhals als Feature.
Klassifikation
Einteilung von Pattern-Recognition verfahren:
- Statistical
Antworten haben eine Wahrscheinlichkeit. Nimm z.B. das Maximum als Antwort.
- unsupervised (z. B. Gaussian-Mixture)
- supervised (z. B. k-means)
- parametric (Wahrscheinlichkeit einer Dichtefunktion)
- nonparametric (z. B. Parlson-Fenster)
- linear
- nonlinear
- Knowledge/Connectionism (z.B. Automat) Sammle Wissen über die Lösung eines Problems und repräsentiere es (z. B. Entscheidungsbaum, Regeln) und triff dann eine “harte” Entscheidung
10. Vorlesung
Klassifikation
Bayes
Das Standardbeispiel für ein überwachtes, parametrisches Lernverfahren ist der Bayes-Klassifikator. Damit ist Dr. Stüker aber unzufrieden, weil Bayes erstmal keine Parameter benötigt. Für gewöhnlich verwendet man dieses Klassifikator mit einer Gauß-Verteilung, daher kommen die Parameter.
Man kann sagen, dass ein heutiges Spracherkennungssystem ein Bayes-Klassifikator mit komplizierter Wahrscheinlichkeitsdichtefunktion (bzw -verteilung), Faltung und Rekurrenz ist.
Er nutzt die a-priori W’keit und klassenbedingte W’keit um posteriori W’keit zu berechnen.
Die klassenbedingte Wahrscheinlichkeit bezeichnet man auch als Likelihood.
Minimum Fehler Regel Der naive Bayes-Klassifikator will Wahrscheinlichkeit für Fehler minimieren. Das heißt, man will den Zähler maximieren, um posteriori zu maximieren.
Man sucht mit diesem Verfahren eine optimale Trennlinie zwischen Verteilungen. Diese heißt auf Englisch Optimal Decision Boundary.
Parzen-Fenster
Dies ist ein Beispiel für ein nicht parametrische Schätzung einer Wahrscheinlichkeitsfunktion. Zu jedem Punkt im Raum zähle die Samples in einem gewählten Volumen, teile sie durch die Gesamtanzahl der Punkte und durch das Volumen.
ASR Pattern
Spracherkennung mit Musterklassifikation. Der Gedanke dabei ist, dass man zum Beispiel für jedes Wort ein Referenzmuster hat und dann eine Mustererkennung auf den Eingabedaten durchführt.
Die Reihenfolge der Merkmalsvektoren ist wichtig, weil Sprache linear in der Zeit läuft. Wähle das Referenzmuster mit der geringsten Fehlerdistanz.
Naiver Ansatz: Normalisiere die Zeit auf die kürzeste Äußerung. Jetzt ist lineare Zuordnung möglich. Sobald die Sprechgeschwindigkeit nicht konstant war funktioniert das wieder nicht.
Sprache ist aber nicht von gleicher Länge. Es variiert die Sprechgeschwindigkeit. Sprache ist bestenfalls “stückweise” linear.
Das heißt, die Abbildung, die wir suchen ist nicht bijektiv, nicht injektiv und auch nicht surjektiv. Vergleiche Alignment aus Maschinellem Übersetzen. Das ist auch nur eine Relation.
Time Warp
Gegeben: Sequenzen $x_1 … x_n$ und $y_1 … y_m$ Gesucht: Relation R mit (i, j) in R wenn $x_i \to y_j$ abbildet.
Das heißt, die Zeitachsen von Referenz und Muster werden auf eine gemeinsame Zeitachse gebracht.
 Figur 11.1 aus Comp449
Figur 11.1 aus Comp449
Für einen gegebenen Pfad R(i,j) ist die Summe aller lokalen Distanzen seine Distanz zwischen x und y. Wie findet man aber den Pfad?
Ähnlich der minimalen Editierdistanz zusammen mit Dynamischer Programmierung. Dafür benötigt man eine DP-Matrix, die die minimalen Editierschritte von $x_1 … x_n$ zu $y_1 … y_n$ enthält. Für jeden Zustand merkt man sich, welcher der beste vorherige Zustand war (Backpointer) und dann nutzt man backtracking, um die Sequenz der Editierschritte zu erhalten.
DTW
Dynamic Time Warp kann ähnlich gelöst werden. Der Zielpfad soll aber einige Einschränkungen haben, die wir aus der Sprache ableiten:
- Der Pfad darf keine signifikanten Teile am Anfang und Ende auslassen
- Da Sprache zeitlinear ist, muss der Pfad monoton steigen
- Lokale Kontinuität: Sprache springt nicht zu stark
- Nähe zur Diagonalen
- Pfad sollte glatt verlaufen, da die Sprechgeschwindigkeit nicht beliebig ist
Welche Schritte sind denkbar?
- symmetrische DTW-Schritte (wie bei Editierdistanz)
- Bakis: vertikal +2 und horizontal +1 -> Sprung
- Itakura: Verbot zweier horizontaler Schritte
Es ist ziemlich viel denkbar…
Diagonalfenster Gemäß der Regeln, dass man Anfang und Ende nicht auslassen soll und dass Nähe zur Diagonalen gewünscht ist, kann man den Suchraum zum Beispiel auf ein Parallelogramm eingrenzen, das die Diagonale beinhaltet. Und dann gestattet man einfach keine Schritte, die von außen nach innen gehen würden. Problem damit: Wenn Stille in der Mitte des Wortes, dann macht man einen Knick nach oben und gelangt vielleicht hinaus. Und bei Start könnte der Suchraum zu klein sein. Vorteil: O(n) statt O(n²)
Um die Probleme zu beheben: Strahlsuche Idee: Ziehe nur diebesten Zustände in Betracht sortiert nach kumulativem Gewicht.. Dabei kann man die Grenze unterschiedlich ziehen:
- konstanter Strahl: nimm die besten k-Pfade
- relativer Strahl: nimm alle, die nur x% schlechter sind als bester Pfad
- absoluter Strahl: nimm alle, die um weniger als x schlechter sind als bester Pfad
- Kombination aus beiden: Maximale Grenze nach oben und abhängig vom aktuell besten
Eine große Frage ist, wie beschreiben wir die Distanz zweier Vektoren?
$d(x,y)$ mit
- L2 $\sqrt(\sum_{i=1}^{n}{(x_i-y_i)^2})$
- L1 $\sum_{i=1}^{n}{| x_i - y_i |}$
- Mahalanobis-Distanz: x und y werden als mehrdimensionale Vektoren auf einer Zufallsvariablen mit Varianz S interpretiert. Wenn S Einheitsmatrix -> normale L2-Distanz, ansonsten: $\sqrt{(x-y)^{T} S^{-1}(x-y)}$
Eine wichtige Frage ist also, ob das Distanzmaß Varianz innerhalb einer Dimension und zwischen den Dimensionen betrachtet.
DTW überwacht? Ja.
DTW parametrisch? Hängt vom Distanzmaß ab.
Wenn man mehrere Trainingsbeispiele als Referenz hat, dann kann man entweder die Trainingsbeispiele vermischen oder alle benutzen und beim Mustervergleich mitteln.
DTW wurde für die Spracherkennung bei alten Handys oder im Embedded Bereich verwendet. Die Wahl der Parameter muss gesucht werden. Auch das kann als Lernverfahren betrachtet werden (Grid Search).
11. Vorlesung
26.11.2018
DTW ist Sprecherabhängig und nur für kleines Vokabular.
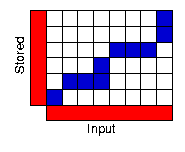
DTW OSDP
One Stage Dynamic Programming ist die Erweiterung von DTW auf eine Sequenz von Wörtern. Das heißt, es gibt dann in-word und cross-word transitions. Dafür muss die zu testende Aufnahme nicht segmentiert werden.
An der Y-Achse werden alle Referenzwörter und an der X-Achse die Aufnahme angetragen. Wenn die obere rechte Ecke eines Referenzwortes erreicht wurde, dann darf zu den Anfängen von allen Referenzwörtern gesprungen werden (inklusive dem Anfang der gleichen Box).
Ein positiver Nebeneffekt ist, dass die Wortsegmentierung quasi nebenbei entsteht.
Für die optimale Lösung muss man einige DP-Matrizen berechnen: $O(N \cdot M^{k_{max}} \cdot K)$.
In der Praxis geringer wegen Strahlsuche oder Einschränkung des Suchraums.
Den Speicherbedarf kann man von Rückzeigern und Distanzen jeder Spalte reduzieren, weil der genaue Verlauf der Pfade unwichtig sein kann, sondern nur die Wortsequenz.
Man braucht eigentlich nur zwei Spalten und eine Liste von genommenen Übergängen (“Rückzeiger bei Wortübergängen”) .
Syntaktische Einschränkung: Jedes Wort hat eine Menge erlaubter Vorgänger. Das reduziert auch den Suchaufwand. Und wenn man die Vorgängermenge abhängig machen möchte vom aktuellen Zustand, dann dupliziere Wörter bis man wieder nur eine Vorgängermenge braucht.
Man hätte damals komplizierte Grammatiken aufbauen können, aber man hat sich lieber auf die stochastische Abstandsbemessung konzentriert.
Gauß
Die Gaußverteilung wird auch Normalverteilung genannt. Sie ist wie folgt definiert:
Mittelwert (1. Moment) ist $\mu$ Varianz (2. Moment) ist $\sigma^2=E((X-\mu)^2)$, wobei $\sigma$ Standardabweichung genannt wird
Wenn man Trainingsdaten X betrachtet und annimmt, dass sie gaußverteilt sind, also $X ~ \mathcal{N}$, dann kann man den Mittelwert und die Standardabweichung schätzen, indem man sie auf den Trainingsdaten berechnet.
In realen Anwendungen sind die Merkmale jedoch höherdimensional -> multivariate Gaußverteilung
Wenn n Trainingsdaten X d-dimensional, dann:
Wobei $\Sigma$ die Kovarianzmatrix ist: für i, j= 1…n
- sie ist symmetrisch und positiv (semi-)definit
- wird als Ellipsoid dargestellt
- die Diagonaleinträge sind für “echte” Normalverteilungen größer 0
- Wenn alle Werte außerhalb der Diagonalen Null, dann sind die Achsen des Ellipsoiden parallel zu den Hauptachsen und das heißt, dass die Dimensionen von X dekorreliert sind
GMM
Gaussian Mixture Model bzw. Gauß-Mischverteilung
Viele reale Prozesse sind aber nicht normalverteilt. Menschliche Sprache auch nicht.
Dafür nähert man die gesucht Wahrscheinlichkeitsverteilung durch ein gewichtetes Aufaddieren von Gaußglocken an.
Um Parameter und Rechenzeit zu sparen, werden nur Diagonalelemente in $\Sigma$ verwendet. Das heißt, dass wir eine Modellannahme machen und zwar, dass die Ellipsoiden nicht gedreht sind. Diesem Nachteil kann man durch mehrere Mischungen von Glocken entgegenwirken.
Man rechnet mit $log p(x)$, da der log monoton, entfällt dadurch die Auswertung der kostspieligen e-Funktion (Taylorreihenentwicklung), aber die wichtigen Eigenschaften von p bleiben bestehen. Meistens wird sowieso nur min und max betrachtet. Der log ist auch numerisch stabiler.
Diese GMM entspricht der Mahalanobis-Distanz zwischen einem gegeben Vektor und dem Mittelwertsvektor. log-skalierte Mahalanobis-Distanz
Auf GMM kann log leider nicht direkt angewandt werden, weil es sich um eine Summe handelt.
Wie findet man Mittelwert und Kovarianzmatrix?
Vektorquantisierung
VQ: Vektorquantisierung
Zwischenspiel. Eigentlich wollen wir für unsere Rechnungen die Varianz und das Kontinuierliche wieder loswerden. Und wir wollen nicht mit dem gesamten Merkmalsraum rechnen.
Abbildung gesucht: $R^n \to N$, um reelle Vektoren auf Index in Repräsentantenvektoren zu beziehen.
Das heißt, wir suchen für jeden Merkmalsvektor x den “nächsten” Referenzvektor $\mu_i$: Dabei entsteht zwangsläufig ein Quantisierungsfehler, den wir minimieren wollen.
Welche Distanz? Wenn man Euklid wählt, dann teilt man den Raum in Voronoi-Regionen ein. Jede Region enthält nur einen Referenzvektor, dieser wird dann für alle Punkte genutzt, die in diese Region fallen. Nachteil: Liefert unintuitive Ergebnisse für Menschen, weil nicht die Varianz der Daten betrachtet wird.
Deswegen nutzen wir die Mahalanobis-Distanz, weil sie die Streuung der Daten mitberücksichtigt. Diese Streuung muss aber im Vorhinein geschätzt werden. Für diese Schätzung muss also klar sein, welchen Referenzvektoren die Trainingsdaten x zugeordnet werden.
Klassifikationsproblem: Gegeben Vektor x finde passenden Referenzvektor $\mu_i$.
Probleme:
- Ausreißer in den Trainingsdaten verzerren Schätzung der Repräsentanten
- Immer nur einen Repräsentanten bis jetzt betrachtet. Wenn ein Punkt aber genau zwischen zwei Repräsentanten liegt, dann würde man lieber mehr betrachten.
K-Nächste Nachbarn: Bestimme für einen neuen Vektor die Klassen der k nächsten Nachbarn. Nimm die häufigst auftretende Klasse für die Klassifikation des Vektors.
Bei vielen Referenzvektoren (16…1024) für viele Klassen (10e4 … 10e5) und einer Dimensionalität der Vektoren (16…48), hat man zu hohen Rechenaufwand.
-> Beschleunigung nötig!
- Keine garantierte Beschleunigung und immernoch korrektes Ergebnis: Las Vegas
- Garantierte Beschleunigung aber nicht unbedingt korrektes Ergebnis: Monte Carlo
Las Vegas und Monte Carlo Beispiel
Standardbeispiel beim Finden eines Minimums: Randomisiertes Ziehen (Sampling) ist abhängig von Annahme über Verteilung der Daten
Beschleunigung von knn:
Early abortion: Breche Distanzberechnungen ab, sobald betrachteter Vektor aktuelles Maximum überschritten hat. Garantiert korrektes Ergebnis und Beschleunigung außer Liste war aufsteigend sortiert.
Organisiere Merkmalsraum in Baumstruktur. An jedem Knoten liegt Entscheidung in Form einer Hyperebene in einer Dimension vor. Wenn Vektor x links, dann links absteigen etc. Die Blätter enthalten dann nur noch weniger nächste Nachbarn.
Die Entscheidungsknoten werden entlang der größten restlichen Varianz getroffen. Berechne Richtung der größten Varianz und teile sie in links und rechts.
Beschleunigung GMM:
- Nur den Wert der nächsten Gaußglocke wählen
- Baumstruktur
- Early abortion
12. Vorlesung
28.11.2018
Woher kommen die Quantisierungsstufen?
Wir wollen sie an die Daten anpassen indem wir Referenzvektoren finden.
Keine gute Idee: Unterteile Raum in Gitter. Das ist , wenn die Daten nicht gleichverteilt
k-means
Unüberwachte k-Mittelwerte:
Gesucht sind die k Referenzvektoren.
- Initialisiere zufällig k Referenzvektoren
- Ordne jedem Trainingsvektor seinen nähsten Referenzvektor zu
- Durchschnitt einer Nachbarschaft ist neuer Referenzvektor
Abbruch nach fester Anzahl Iterationen oder Distanz aller Vektoren unter Schwellwert oder durch Kreuzvalidierung mit gelabelten Trainingsdaten.
Learning VQ
Überwacht
Gesucht: Referenzvektoren
Bewege Referenzpunkt hin zu Objekten seiner Klasse und weg von den anderen. Wie groß soll die Bewegung sein?
Das erinnert an die Backpropagation, bzw. davon an die Bewegung auf der Fehleroberfläche.
LVQ2: Bestimme die beiden nächstgelegenen Repräsentaten. Wenn beide unterschiedlich, dann verschiebe Referenz.
LVQ3: Auch Update wenn beide Repräsentanten gleich weit weg
LVQ kann als ein sehr einfaches neuronales Netzwerk interpretiert werden.
Unter dem Strich kann k-means für die Initialisierung von GMM genutzt werden. Wir brauchen dafür: $\mu, \sigma$ und die Gewichtung der einzelnen Glocken.
Stochastik ASR
Wir modellieren die Variabilität der Sprache mit Statistik. Für die Zeitvariabilität hatten wir DTW eingeführt.
Für die unterschiedliche Ausprägung der Merkmale die Mahalanobis-Distanz. -> Bei einem großen Vokabular (400.000 Wörter) benötigen wir für jedes Wort eine Referenz. Und von jedem Wort am besten 1000 Aufnahmen um der Variabilität gerecht zu werden. Das wäre 4 x 10e8 Wörter. Schwer zu sammeln! Und die Grammatik fehlt da auch noch.
Stattdessen hätten wir lieber kleine Bauteile, die zu beliebigen Wörtern zusammengesetzt werden können.
Fundamentalformel
Dr. Stüker erwartet, dass man diese Formel nachts um 3:00 aufsagen kann:
Naiver Bayes-Klassifikator:
Anwendung der Bayes-Formel:
Weil es um die Maximierung geht, können wir nur den Zähler betrachten
$\hat{W}$ ist die Sequenz von Wörtern. W ist alle möglichen Sequenzen. X ist die “Aufnahme” nach der Vorverarbeitung.
Also: Wähle $\hat{W}$ als wahrscheinlichste Wortfolge gegeben der Aufnahmedaten X.
Nebenspiel: Warum ist die Sequenz nicht unendlich groß?
- maximale Sprechgeschwindigkeit
- Diskretisierung (-> mehr als ein Wort pro Frame)
- Inventar der Phoneme ist endlich
| $P(W | X)$ schwer zu modellieren, deswegen Bayes-Formel angewendet. |
Wir sind nicht interessiert, wie wahrscheinlich W ist, sondern wie sie aussieht. -> nur Zähler maximieren
$\hat{W}$ heißt Hypothese und X Merkmalsvektor.
P(X|W) ist da akustische Modell: Wie klingt die Wortfolge, wenn sie bei mir ankommt? Das ist die klassenbedingte Wahrscheinlichkeit einer Aufnahme (a-priori)
P(W) ist Sprachmodell: Welche Wortfolgen sind wie wahrscheinlich? Die Wahrscheinlichkeiten von Sequenzen (a-priori) -> kann man zum Beispiel aus Textkorpora herausbekommen
Mit Bayes minimiert man die Wahrscheinlichkeit für einen Klassifikationsfehler. Also die “Satzfehlerrate” (nur komplette Sequenzen). Sie sind entweder richtig oder nicht. Was wir nicht minimieren ist soetwas wie eine Levenshtein-Distanz.
Klassifikatoren mit Wortfehlerrate zu bauen ist schwierig und wurde erst später realisierbar (kommt noch in der Vorlesung).
MM
Markov-Modell
Annahme: Sprachproduktion ist ein stochastischer Prozess.
Gegeben ist ein Wahrscheinlichkeitsraum $( \Omega, F, P)$ mit:
- Ergebnisse Omega
- Ereignisse F
- Wahrscheinlichkeiten von Ereignissen
F Sigma-Algebra
Ereignismenge ist abgeschlossen ggü. Vereinigung, Komplementbildung…
Definition Zufallsvariable…
F-Z-messbar…
Zustände Z
Wenn t ganzzahlig, dann ist es ein zeitdiskreter stochastischer Prozess.
Für ASR nutzen wir zeitdiskrete Markov-Ketten.
Eine Markov-Kette n-ter Ordnung: $X = (X_t)t=1..n$
Annahme: Zustandsübergang ist nur von den vorherigen n-1 Zuständen abhängig.
Für ASR nutzen wir noch einfachere Ketten: Markow-Kette erster Ordnung (also n=1)
- Anfangsverteilung: $\mu$ Wahrscheinlichkeitsvektor der Anfangszustände: $\pi = (\pi_1 .. \pi_n)$ mit jedem $\pi_i >= 0$
- $\sum \pi_i = 1$
- Übergangswahrscheinlichkeiten $p_{ij}(t) := P(X_{t+1}=s_j | X_t = s_i)$
Wenn man die Abhängigkeit von t entfernt, dann kommt man zur homogenen Markow-Kette: $p_ij (t) = p_ij \forall t$
Diese ist vollständig beschrieben durch:
- Zustandsfolge S
- Anfang $\mu$
- Übergang $p_ij$
Ein einfaches Beispiel dafür ist ein Wettermodell.
Man kann dann auch Folgen von Zuständen zufällig generieren. Siehe Namensgenerator. Die Namen klingen richtig. Der Mensch scheint ebenfalls eine Modellierung dieser Art zu machen. Das ist als Bestätigung der These zu sehen, dass Sprache als stochastischer Prozess modelliert werden können
Problem: Bei Sprache sieht man aber keine Buchstaben sondern Merkmalsvektoren. Wenn man ein Wort ausspricht, dann durchläuft man im modell Zustände. Diese Zustände könnten Phoneme sein.
Es ist aber nicht beobachtbar, welche Phonemzustände durchschritten wurden.
HMM
Hidden Markov Model
Wir wissen nicht, welche Zustände Beobachtungen produzieren.
Wenn Münzwurf hinter Vorhang passiert, dann können wir nicht den Zustand beobachten. Eine Person hinter dem Vorhang sagt uns aber, was das Ergebnis war.
Aufgabe an die Zuschauer ist nach einer Sequenz von beobachteten Merkmalen, die Zustandsfolge herauszufinden -> ASR
Dazu nächste Vorlesung mehr.
Literaturempfehlung für HMM:
A tutorial on HMM and selected applications Das Tutorial ist immernoch gut. Die Anwendungsfälle eher nicht mehr.
Neuerdings gibt es folgenden Ansatz: P(W|X) direkt mit Neuronalem Netz und sehr vielen Daten schätzen.
2000: Waren 80h gelabelte Trainingsdaten sehr viel 2018: Heute sind es 140.000 h aus einer speziellen Domäne. Nur die großen Firmen haben die Rechenkapazität und Daten für solches Training
Für jede Domäne, die nicht so viele Daten angesammelt hat, sind die HMMs weiterhin ein sehr guter Kompromiss.